GMM(Gaussian Mixture Model)
什么是高斯混合模型?
首先我们有k个高斯模型,他们分别为$ N(\mu_1, \sigma_1^2), N(\mu_2, \sigma_2^2), …, N(\mu_k, \sigma_k^2) $
我们按照一定的比例从N(μj,σj2)这个高斯函数中取了比例为ϕj的一些样本。
按照经验可得,∑j=1kϕj=1,即所有比例之和为1。
p(z(i)=j)=ϕj表示在z=j这个cluster的概率,如果是hard assignment,则用I(z(i)=j)表示。如果在这个cluster,即则z(i)=j,则概率为1,反之不在这个cluster则为0。
p(x(i)∣z(i)=j)=pnorm(x(i);μj,σj)表示在j这个高斯分布中的取到x的概率,如
每一个x(i)都对应k个zj(i)
基本参数和分布
input: $$ {x^{(1)}, …, x^{(n)}} $$
latent variable:
{z(1),...,z(n)}, z(i)=(z(i)=1,z(i)=2,...,z(i)=k)
换而言之,每个z(i)都对应一个x(i),z(i)满足多项式分布,且可以拆分为分属不同k的z。通过分属不同k的z来拼凑出大的z,从而得到x。
joint distribution
p(x(i),z(i))=p(x(i)∣z(i))p(z(i))
其中,z(i)~ Multinomial(ϕ)多项式分布,where ϕj≥0,∑j=1kϕj=1。
x(i)∣z(i)=j∼N(μj,Σj)
z(i)指示了每个x(i)是从那个k Gaussians来的。
p(z)表示probability of choose cluster z,也就是density of mixture model
p(z(i)=j)表示在z=j这个cluster的概率
i表示第几个data的index,x表示data
j表示第几个cluster的index,z表示cluster
参数ϕj提供p(z(i)=j),x(i)∣z(i)=j∼N(μj,Σj),即x|z满足某一个高斯分布,N()为高斯分布
likelihood of data
ℓ(ϕ,μ,Σ)=i=1∑nlogp(x(i);ϕ,μ,Σ)−−−(1)=i=1∑nlogz(i)=1∑kp(x(i)∣z(i)=j;μ,Σ)p(z(i)=j;ϕ)−−−(2)
为了解决(1),所以我们引入了z从而将这一个概率拆为两个部分的概率的相乘,从而得到(2)
其中;左侧表示变量,右侧表示参数,,表示并列。x∣z;μ,Σ中,|的右侧表示整体范围(即z=j的范围内),左侧x表示在右侧那些范围中x的概率
如果z(i)已知的话,即如果我们知道zi来自于哪个高斯分布,换句话说我们把j固定了下来,则式子可以化简为
ℓ(ϕ,μ,Σ)=i=1∑nlogp(x(i)∣z(i);μ,Σ)+logp(z(i);ϕ)−−−(3)
maximum函数(3),通过求偏导=0,从而算出结果为:(此时固定了j)
ϕj=n1i=1∑n1{z(i)=j}
μj=∑i=1n1{z(i)=j}∑i=1n1{z(i)=j}x(i)
Σj=∑i=1n1{z(i)=j}∑i=1n1{z(i)=j}(x(i)−μj)(x(i)−μj)T
从上图可以看出来,z(i)可以视为class label的作用,所以只要知道z(i)就可以都求出来了,所以我们通过使用EM方法来求z(i)
EM (Expectation-Maximization) algorithm for density estimation
(E-Step) 猜测z(i),cluster assignment
For each i,j, set
wj(i):=p(z(i)=j∣x(i);ϕ,μ,Σ)
这个ωj(i)表示我们对z(i)的猜测。因为我们要求z,所以把z放在|的左边
通过Bayes 法则,我们可以得到:
p(z∣x)=p(x)p(x∣z)p(z)
p(z(i)=j∣x(i);ϕ,μ,Σ)=∑l=1kp(x(i)∣z(i)=l;μ,Σ)p(z(i)=l;ϕ)p(x(i)∣z(i)=j;μ,Σ)p(z(i)=j;μ,Σ)p(z(i)=j;ϕ)
f(x)=(2π)kdetΣ1exp(−21(x−μ)TΣ−1(x−μ))
p(x(i)∣z(i)=j;μ,Σ)来自于density of Gaussian with mean μj和convarianceΣj,表示如果xi来自于高斯分布j,则从该模型中取到x的概率
p(z(i)=j;ϕ)=ϕj,表示来自于j这个高斯模型的概率
(M-Step) 基于猜测update model的parameter(MLE)——soft assignment
Update the parameters:
ϕj:=n1i=1∑nwj(i)
μj:=∑i=1nwj(i)∑i=1nwj(i)x(i)
Σj:=∑i=1nwj(i)∑i=1nwj(i)(x(i)−μj)(x(i)−μj)T
Restriction
Σj=σ2I
其中σ2→0则原函数化简为k-means
从概率的角度而言,高斯图像无限逼近脉冲函数,只有靠近中心的位置才有数值,其余都很小。因此针对于某一个高斯分布,概率很大,对其他而言,概率很小。所以从w的数值而言,按照贝叶斯分布的那个分子分母公式,这个数据只有在某一个高斯分布里面才会很大,其他都无限接近于0.
从cluster的角度而言,sigma变为0表示GMM椭圆的cluster边界变为k-mean圆形的边界(或者说椭球形变为球型)
K-means的进阶方法
不再使用hard cluster assignment c(i),而是使用soft assignments ωj(i)
作业代码里面,w是mxk的矩阵,里面装着xi属于高斯分布j的概率。如果要变成hard cluster,只要遍历xi在所有k个高斯分布里面概率,找到最大概率的那个高斯分布,然后就认定是这个高斯分布,除此以外的概率都是0,所以矩阵退化为mx1的向量。
GMM求解
GMM可以通过run EM或者min loss function来求解
其他
从cluster l中观测到x的概率:
P(x)=∑P(x,z=l)=∑P(x∣z=l)P(z=l)
单个参数,用求导
多个参数,用MLE或者EM
reference
https://mas-dse.github.io/DSE210/Additional Materials/gmm.pdf
什么是高斯混合模型
https://www.bilibili.com/video/BV12d4y167ud/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1Dd4y167pZ/?spm_id_from=333.788.recommend_more_video.-1&vd_source=2029748cdca0ccea25511170cf7a00c3
两个高斯模型组成的,选到模型1的概率为 π,选到模型2的概率为 1−π。下面就是选到了x模型的概率
p(x;π,σ1,σ2,μ1,μ2)=πpnorm(x;μ1,σ1)+(1−π)pnorm(x;μ2,σ2)
对其进行 log,因为 log(x) 是函数,所以求 maxx 和求 maxlog(x) 一个道理
log(L(x;π,μ1,μ2,σ1,σ2))=∑log(πpnorm(x;μ1,σ1)+(1−π)pnorm(x;μ2,σ2))
p(x,z)=p(x∣z)p(z)
where,
z∈{0,1},p(z=1)=π,p(x∣z=1)=pnorm(x;μ1σ1),p(x∣z=0)=pnorm(x;μ2,σ2)
z和x同时发生的概率=z发生的概率*x发生的概率然后求和
log(L(p(z,x;π,μ1,μ2,σ1,σ2)))=i∑zilog(πpn(xi;μ1,σ1))+(1−zi)log((1−π)pn(xi;μ2,σ2))
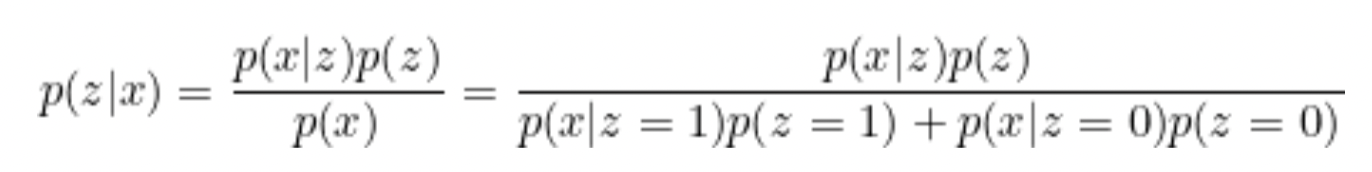
期望=log(p(x,z))的概率乘以是否发生,也就是p(z=1|x)
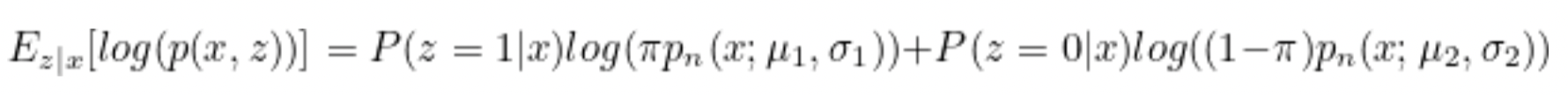
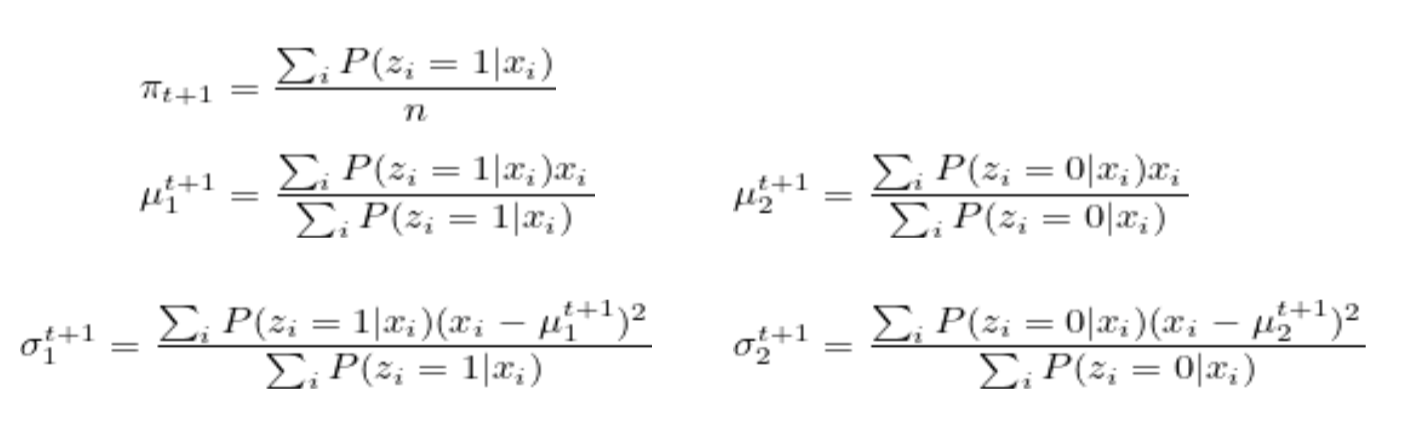
声明:此blog内容为上课笔记,仅为分享使用。部分图片和内容取材于课本、老师课件、网络。如果有侵权,请联系aursus.blog@gmail.com删除。