概念
目的:降维
input x⊂Rd,{x(i);i=1,...,n}
output Z⊂Rk
F:X→Z, k<<d
i 表示有几个sample(共n个),j表示有几个feature(共d个)
preprocess|数据的预处理
目的:将所有的feature normalize为mean=E[xj(i)]=0,variance=Var[xj(i)]=1的数据
方法:
xj(i)←σjxj(i)−μjwhere, μj=n1i=1∑nxj(i), σj2=n1i=1∑n(xj(i)−μj)2
如果我们能够确定不同的feature都有相同的scale,则可以表示
?parameter estimation使用的是EM算法
计算major axis of variation u
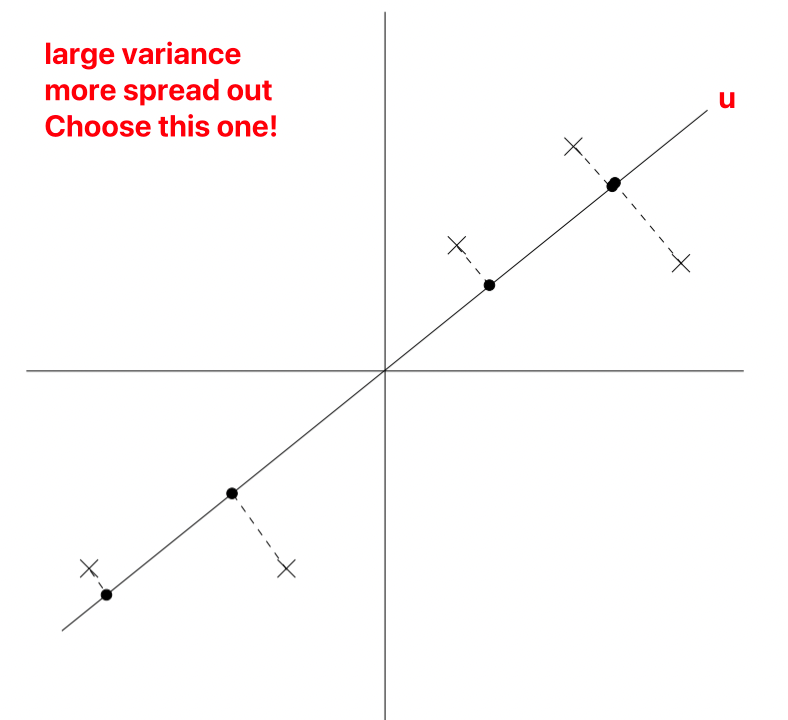
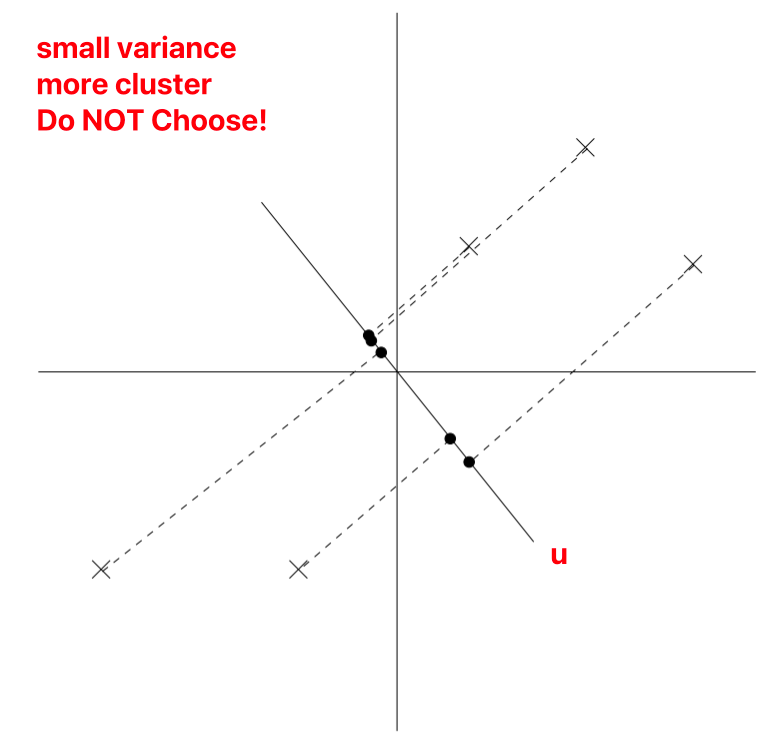
u为unit vector,x为sample,在图上标示为不同的点
在projection(将2d降维1d的时候),为了保留更多的信息,我们选择projection data 的variance较大的,也就是投影点分布更加均匀的。
因为经过normalize了,所以u一定经过原点。
Projection Variance Max|投影最大化
点x在向量u上面点投影是 xTu,
Projection的求法:
∣∣Proju(x)∣∣2=∣xTu∣
Variance的求法:
Var(Proju(x))=∣xTu∣2
所有点x在单个u上面投影的variance:
n1i=1∑n(x(i)Tu)2=n1i=1∑nuTx(i)x(i)Tu=uT(n1i=1∑nx(i)x(i)T)u=uTΣ^u
如果∣∣u∣∣2=1,则principal eigenvector可以化简为Σ^=n1∑i=1nx(i)x(i)T,即
∣∣u∣∣2=1maxuTΣ^u=λ1
其中 λ_1 表示first eigenvalue of Σ^ principle eigenvalues,此时的u取的是1st principal eigenvector of Σ^
小结
x最好的1D方向是 1st eigenvectors of covariance,即 v1Σˉ。可以使用pytorch的torch.lobpcg函数
如果我们想把数据投射到1D中,则选择 u to be principal eigenvector of Σ。
降维投射完毕的数据:X.mm(V) ,其中V为前k个eigenvector,size (d, k)。X 从 m×d 维度降为 m×k
如果我们想把数据投射到 k D中,
方法一:选择 $ u_1, u_2, …, u_k$ to be the top k eigenvectors of Σ。
u1,u2,...,ukmaxi=1∑u∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣⎣⎢⎢⎢⎡u1Tx(i)u2Tx(i)...ukTx(i)⎦⎥⎥⎥⎤∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣22=v1,v2,...,vk
方法二:
u1,u2,...,ukmini=1∑n∣∣xi−xˉi∣∣22=i=1∑n∣∣xi−l=1∑k(ulTxi)ul∣∣22
其中 xˉi 表示reconstruction example given by basic component
声明:此blog内容为上课笔记,仅为分享使用。部分图片和内容取材于课本、老师课件、网络。如果有侵权,请联系aursus.blog@gmail.com删除。