BME | Machine Learning - K means Clustering
K means Clustering
Assumptions
There are subsets , and data points, and all data points satisfy the following conditions:
- Each point belongs to a cluster.
- Each cluster is non-overlapping.
Defining Distance
where denotes the number of observations in the kth cluster.
The goal is to minimize the pairwise squared distance for each cluster.
where
Iterative Objective
Algorithm | Lloyd’s algorithm

Not necessarily optimal because if the initialized points are not good, it can converge to a suboptimal clustering.
- input:
- initial:
- loss function
-
If not yet converged,
- Update centroids.
- Update clusters.
Choosing k: Determining Size
If , it is necessary to increase k, i.e., .

Choosing initial cluster assignment
- Everyone tries several random initial cluster assignments and then selects the one with the lowest result using Lloyd’s algorithm.
- Or, through the k-means++ method: randomly select the first data point as a centroid, then choose subsequent centroids based on a distance-weighted distribution from the already selected centroids.
Decision Boundaries
The region can be computed using two cluster centroids , .
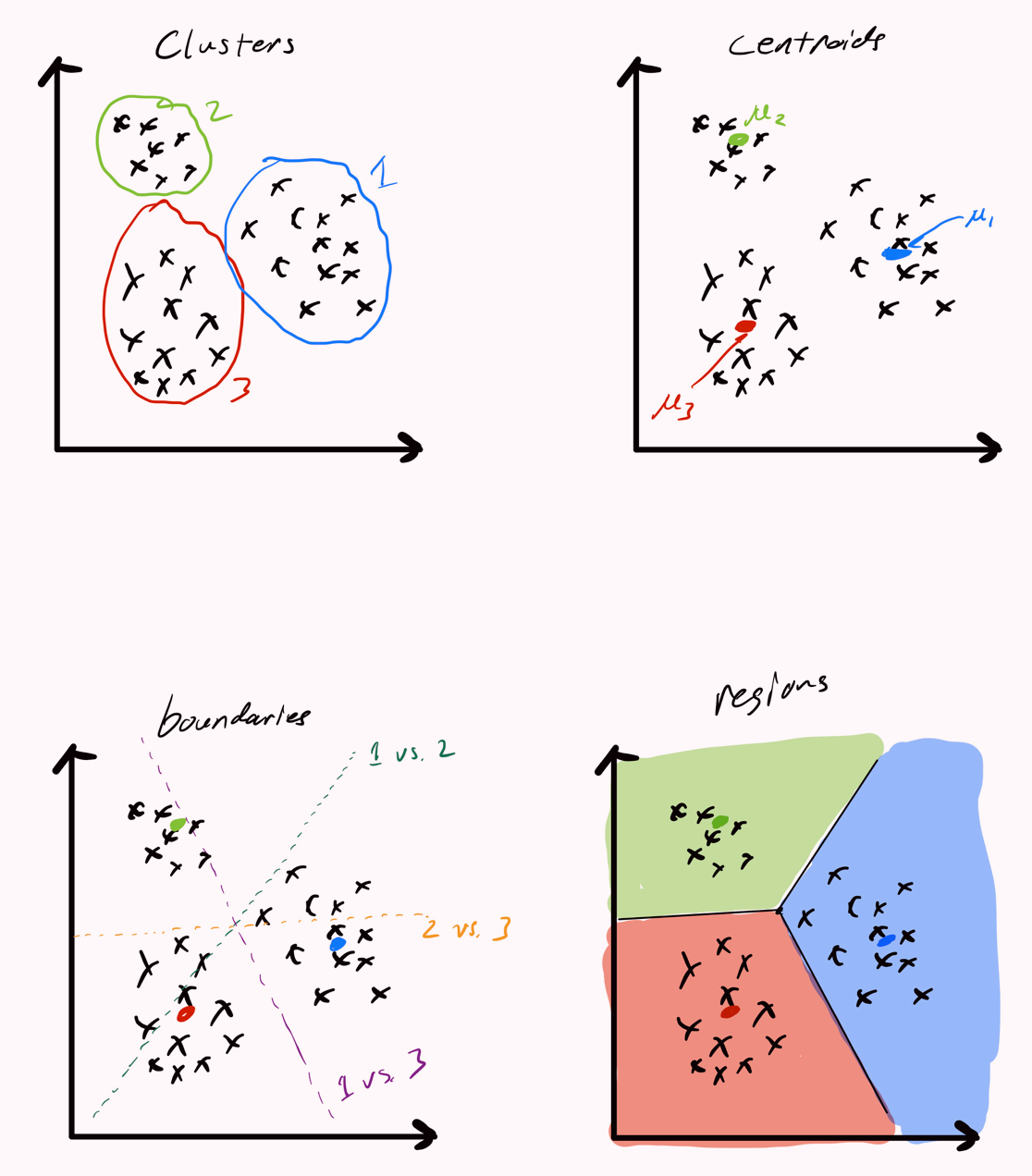
Reference:
https://www.cs.cornell.edu/courses/cs4780/2022sp/notes/LectureNotes04.html
Note: The content in this blog is class notes shared for educational purposes only. Some images and content are sourced from textbooks, teacher materials, and the internet. If there is any infringement, please contact aursus.blog@gmail.com for removal.